Transcribing My Degree: Harnessing AI Speech Recognition with OpenAI's Whisper API
As a university student, I often wished to have my lectures transcribed into text, creating a comprehensive and easily accessible reference of all my lecture material.
The benefits of converting this body of content to its written form are numerous:
- Easy preservation of lecture content
- Faster comprehension and review
- Searchable text for quick reference
- Portability and effortless backup: recorded lectures may require hundreds of megabytes, while text files only need a few kilobytes
For that purpose, I diligently recorded pretty much every lecture or seminar I attended during my time at the university. However, with hundreds of hours of audio files, this is easier said than done, or is it…?
My Lecture Library: an Overview
To put the challenge into perspective, we need to gauge this task through both a qualitative and a quantitative lens.
Let’s start with the numbers first. My lecture audio library comprises 151 recorded sessions (15GB). With an average duration of 50 minutes per class, there is more than 125 hours worth of content altogether.
I captured all the recordings in MP3 format with a mid-range voice recorder from various locations in different lecture rooms: I would usually try to sit at the front row (what a nerd amirite), closest to the lecturer, to get the best sound possible. This was not always possible though, as sometimes I had to sit at the back, crammed between people or in older lecture theatres with poorer acoustics. Thus, the quality of the recordings ranges wildly from “suboptimal” to “pretty rubbish”.
To visualise how noisy the source material is, take a look at the following spectrogram from one of my recorded lectures:
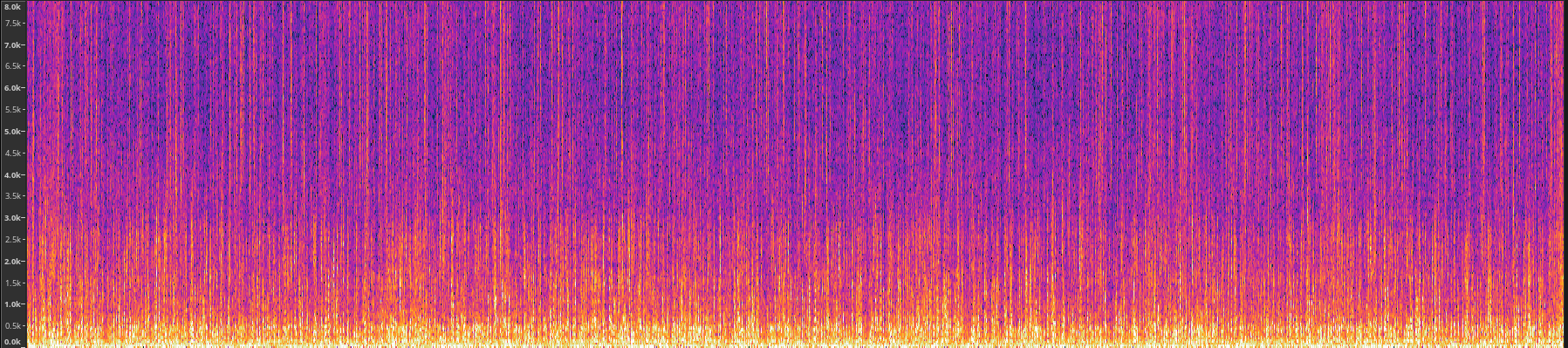
I am no sound engineer myself. In case you, dear reader, are not one either, let me point out the most important things to interpret on this graph so that you can better appreciate the bad quality of my source audio material.
This spectrogram was rendered using Tenacity. Higher intensity areas are shown on a brighter, yellowish hue, whereas areas, where the sound signal is weaker are shown in purple or black (if no signal at all was registered). Knowing this, we can appreciate a higher average intensity level across all frequencies in this spectrogram. This is indicative of poor recording quality and/or large amounts of background noise, as there are a lot of sounds present in undesirable regions that sit well outside the normal 80-255 Hz human voice range.
For comparison, take a look at this other spectrogram obtained from a studio-quality BBC podcast episode:
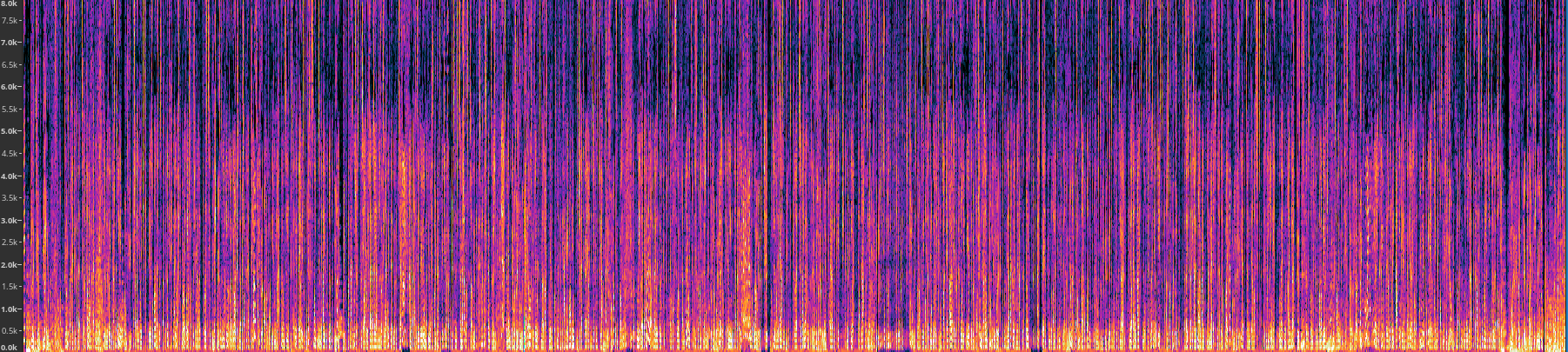
The graph looks neater, with many more darker stripes above 500 Hz. This latter spectrogram depicts a much cleaner sound profile, as you would expect in a professionally produced podcast.
The quality of my lecture audios didn’t bother me much back when I was recording them as I was happy to sit down at home after class and carefully listen to them while reviewing my notes (neeerd). However, these unclean recordings can be a real nightmare for an automated tool to transcribe effectively. Surely somebody would be up for the task, though?
Early Attempts: AWS and GCP
My initial experiments with lecture transcription involved a couple of iterations of both the Amazon Transcribe and Google Cloud Speech-to-Text APIs —both launched in 2017— which yielded unimpressive results.
Amazon Transcription services were particularly underwhelming: the service was awkward to use and the list of supported file types rather limited. Regrettably, I conducted these experiments a few years ago and did not retain any records to showcase the performance of the AWS service at that time.
However, I revisited the Google Cloud Speech-to-Text service while researching for this article so I could portray a fair picture of what the state-of-the-art was when OpenAI launched their speech recognition API.
Speech Recognition in the Google Cloud
During my Google Cloud transcription trial, I utilised the video premium transcription model, which, according to Google, is particularly well suited to processing difficult audio files with a lot of background noise. Google Cloud Platform’s (GCP) basic audio transcription services are relatively simple to use on the web-based GCP Console. However, they provide fewer features compared to the APIs they integrate against. One notable feature missing in the basic transcription services is the availability of the aforementioned video model.
There are two main APIs to obtain transcriptions from an audio file in the Google Cloud:
speech:recognize: synchronous requests for files up to 1 minute long.speech:longrunningrecognize: for requests to transcribe files longer than 1 minute. It delivers results asynchronously.
I submitted a job to the long-running API for a 1-hour MP3 recording using this cURL command:
curl -s -H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \
-H 'X-Goog-User-Project: <project-id>' \
https://speech.googleapis.com/v1p1beta1/speech:longrunningrecognize \
--data '{
"config": {
"encoding": "MP3",
"sampleRateHertz": 44100,
"languageCode": "en-US",
"model": "video"
},
"audio": {
"uri": "gs://scribesgfaultcom/audio-files/lecture.MP3"
}
}
Even though multiple different codecs are supported, surprisingly, MP3 hasn’t been promoted out of beta status since the last time I used this API in 2021. Moreover, the only English variant supported by the video model is en-US, which limited accuracy for me, as my lectures mainly feature non-American English speakers.
According to the GCP documentation, it takes half the length of the source audio for a long-running transcription job like the one above to complete. This statement was somewhat accurate as it took 22 minutes for me to obtain a result for a 1h 2m audio upload. The Google speech recognition API sends its output in JSON format with a bunch of metadata mixed in so I’ve extracted just the transcription content below for readability. You can access the full unadulterated transcript here.
it's nice to have the cameras can put in this speech reusable packages of code and the key difference between something like a paradigm the component side I'm stumbling steps to look inside wake up to use to go to the helicopters whose components used to some component and its features
for example last week There's a gray area in between for summer class parties and things you can have it inside components and we use our Concepts inside the house of the languages inside some component systems such as about that which you just prefers to paradigms so we will have one as well as time there was an interim basis as a logical way to locate
one of us to government creating lots of compliments with names and we couldn't decide we're going to be seeing some of you might decide on the same name particular feature which has two significant building you can poop out logically under some higher hierarchy then we solidified which version of component of to Canadian converting
it's a bigger batch of loading a code change management in terms of metadata and get my idea but in systems like dotnet and Java balaclava you're going to die linking it one time but we can accomplish together it's use your benefits of traditional Burger sort of approaches we also have some new problems
so one of the issues with this problem panelist has to do with waiver getting totally last 10 20 years but problems in deploying software but people were deploying using languages with different names and somebody's rights you have a package with a similar sort of library with someone named item same name and we've installed but I didn't know which
special libraries for us to use
I was unable to find a sensible cut-off point for this excerpt given how nonsensical and incomprehensible the majority of it is. I am fairly disappointed to see Google have hardly made any improvements to their speech recognition APIs in any areas that would matter since the last time I experimented with them 2 years ago: the Google speech recognition models remain highly inaccurate and sensitive to audio quality, slow and awkward to use.
In summary, both the AWS and Google transcription tools have failed to achieve their objective of effectively processing technical content, where accuracy in abbreviations and specialized terms is crucial.
To give credit to AWS, I have not reevaluated their APIs since my initial tests in 2017, and they may have made significant advancements since then. However, the recent launch of OpenAI’s Whisper API has captured my interest far more than its predecessors ever did so I’ve not felt the need to give them a second chance.
The OpenAI Whisper API
OpenAI launched the ChatGPT API last month, which was enthusiastically received by a community that had been eagerly anticipating its arrival. However, I was more intrigued by the public release of the speech-to-text model API that accompanied this announcement, the Whisper API.
Based on OpenAI’s Whisper model, the Whisper API is a simple API interface that converts voice recordings to a textual form of some sort. Its key features comprise:
- Transcription and translation services in more than 50 different languages
- Support for many different audio formats (including MP3!)
- Bindings available for several programming languages such as Python or JavaScript
- PAYG model: no need to spend a fixed amount of money upfront to purchase service credits or tokens, as other OpenAI services such as DALL-E require
After a couple of quick experiments, I found the accuracy of the model was good, like really good. And it was fast, like really fast. Easily 10x faster than its Google counterpart. I was convinced there was a lot of potential in this tool so I decided to sacrifice a couple of dollars for the sake of science and start a little project to transcribe all the lectures from my library.
Building a prototype transcriber in Node.js
Obtaining transcripts from the Whisper API in Node is rather easy. All you need to do is install the openai npm package, configure it with your OpenAI API key and send your first API request pointing to an open file read stream, as I show below.
import { Configuration, OpenAIApi } from 'openai';
const config = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(config);
(async function() {
const res = await openai.createTranscription(
file,
'whisper-1',
undefined,
undefined,
undefined,
'en',
{
// Allow request payloads of up to 25 MB, the maximum accepted by Whisper API
maxBodyLength: 25 * 1024 * 1024,
}
);
})();
This will return the entire transcript for the submitted audio (up to 25 MB) as a single, contiguous text response.
Due to privacy and data protection concerns, I won’t share the entire transcript output, but this excerpt should give you a good idea of what the rest of the it looks like (I apologise in advance to your horizontal scroll bar):
We've described how to characterize components, as well as reusable packages of code. And the key difference between something like an OO paradigm and a component paradigm, is a standalone concept. So in OO you have to look inside a white box for use to be able to inherit properties. With components, you just use that component and its features. I saw some examples last week. There's a grey area in between, because some of the class properties and things you can inherit inside components. And we use OO concepts inside the, so how the program manages inside some component systems, such as.NET, which uses both of those paradigms. So we've been working on, as well, on component namespaces as a logical way to locate components. So at a particular moment, creating lots of components with names that we put as a side. If you're in a big team, you might decide on the same name for a particular feature, which has to seem different. But you can group that logically, under some higher hierarchy. And then you can identify which version of component you can name and refer to. I'll do a bit about package loading of code, which is managed in terms of metadata.
If you want to see my Node implementation in full, the source is available on sourcehut.
Preprocessing the source audio files for consumption
One key limitation of the Whisper API is that it doesn’t allow payloads larger than 25 MB. Therefore, it is necessary to split up the source file into smaller fragments if it exceeds this limit. With an average size of 100 MB, my lecture recordings needed some preprocessing before I could upload them to the model.
OpenAI recommend using pydub to transform large audio files into a size suitable for consumption, so I wrote a little Python script to do that.
from fileinfo import FileInfo
from pydub import AudioSegment
class AudioFile:
def __init__(self, file, fileinfo: FileInfo) -> None:
print("Loading audio file...")
self.file = AudioSegment.from_file(file)
self.fileinfo = fileinfo
def get_duration_minutes(self):
return len(self.file) / 1000 / 60
def export_chunk(self, chunk, output_path: str):
print(f"Exporting chunk to {output_path}...")
chunk.export(output_path, format=self.fileinfo.file_ext[1:])
def export_to_chunks(self, chunk_duration_mins, output_path="."):
print(f"Output path: {output_path}")
audio_chunks = self.file[::chunk_duration_mins]
print("Splitting audio into chunks")
chunk_filename_idx = 1
chunk_paths = []
for chunk in audio_chunks:
chunk_path = f"{output_path}/{self.fileinfo.file_basename}-chunk-{chunk_filename_idx}{self.fileinfo.file_ext}"
chunk_paths.append(chunk_path)
executor.submit(self.export_chunk, chunk, chunk_path)
chunk_filename_idx = chunk_filename_idx + 1
return chunk_paths
Switching to a full Python implementation
I picked Node for the actual transcription part out of habit, as it’s a language I’m very comfortable with. However, I soon ran into all sorts of boring problems getting the output of my Python audio splitter script to be fed correctly into the Node transcriber. To save me the trouble, I decided to rewrite the transcriber component in Python and combine it with the audio splitter I already had to allow for much easier audio file processing.
Therefore, the Node implementation I showed you earlier ended up rewritten to something like this:
import asyncio
import openai
import tempfile
import splitaudio
import fileinfo
MAX_FILE_DURATION_MINS = 20
CHUNK_DURATION_MINS = 20 * 60 * 1000 # 20 mins
async def transcribe(file_path):
audio = None
file_duration_mins = 0
with open(file_path, "rb") as file:
audio = splitaudio.AudioFile(file, fileinfo.FileInfo(file_path))
file_duration_mins = audio.get_duration_minutes()
if file_duration_mins > MAX_FILE_DURATION_MINS:
with tempfile.TemporaryDirectory() as dir:
chunk_paths = audio.export_to_chunks(CHUNK_DURATION_MINS, dir)
transcription = ""
fetch_transcription_tasks = []
for cp in chunk_paths:
fetch_transcription_tasks.append(get_transcription(cp))
transcriptions = await asyncio.gather(*fetch_transcription_tasks)
transcription = ''.join(transcriptions)
return transcription
else:
with open(file_path, "rb") as file:
return await fetch_transcription(file)
async def get_transcription(filepath):
with open(filepath, "rb") as file:
return await fetch_transcription(file)
async def fetch_transcription(file):
print("Fetching transcription for file...")
transcription = await openai.Audio.atranscribe("whisper-1", file, language="en")
return transcription["text"]
If we isolate the segment from the code above that is specific to Whisper API, it’s barely different to Node, with the exception that the Python script can capture the OPENAI_API_KEY environment variable and pass it into the API call automagically.
async def fetch_transcription(file):
print("Fetching transcription for file...")
transcription = await openai.Audio.atranscribe("whisper-1", file, language="en")
return transcription["text"]
Formatting the output
This was enough to obtain fairly clean and accurate transcripts of different recorded lectures. However, it needed a final typesetting post-processing step to arrange the amorphous stream of transcript text into a set of readable paragraphs. I created the paragraphs.py script for this purpose.
#!/usr/bin/env python
import sys
import textwrap
def split_text_into_paragraphs(text, max_line_length=120, lines_per_paragraph=10):
wrapped_lines = textwrap.wrap(
text,
width=max_line_length,
break_long_words=False,
break_on_hyphens=False
)
paragraphs = []
for i in range(0, len(wrapped_lines), lines_per_paragraph):
paragraph = "\n".join(wrapped_lines[i:i + lines_per_paragraph])
paragraphs.append(paragraph)
return "\n\n".join(paragraphs)
def main():
long_text = ""
filepath = sys.argv[1]
with open(filepath, "r") as file:
long_text = file.read()
formatted_text = split_text_into_paragraphs(long_text)
print(formatted_text)
if __name__ == "__main__":
main()
This converts the single-line output from my previous example into something easier on the eye:
We've described how to characterize components, as well as reusable packages of code. And the key difference between
something like an OO paradigm and a component paradigm, is a standalone concept. So in OO you have to look inside a
white box for use to be able to inherit properties. With components, you just use that component and its features. I saw
some examples last week. There's a grey area in between, because some of the class properties and things you can inherit
inside components. And we use OO concepts inside the, so how the program manages inside some component systems, such
as.NET, which uses both of those paradigms. So we've been working on, as well, on component namespaces as a logical way
to locate components. So at a particular moment, creating lots of components with names that we put as a side. If you're
in a big team, you might decide on the same name for a particular feature, which has to seem different. But you can
group that logically, under some higher hierarchy. And then you can identify which version of component you can name and
refer to. I'll do a bit about package loading of code, which is managed in terms of metadata. And you get my idea, but
Finally, this small shell script ties it all together:
#!/usr/bin/env bash
# transcribe.sh
function print_normalised_filename() {
local filename="$1"
echo "${filename}" | tr "[:upper:]" "[:lower:]" | tr -d " "
}
SCRIPT_PATH="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd -P)/$(basename "${BASH_SOURCE[0]}")"
SCRIPT_DIR="$(dirname "$SCRIPT_PATH")"
for transcript in "$@"; do
filename=$(print_normalised_filename "${transcript}")
output="$(${SCRIPT_DIR}/paragraphs.py "${transcript}")"
echo "${output}" > ./${filename}
rm "./${transcript}"
done
Example usage:
./transcribe.sh ~/uni-lecture-transcripts/year2 ~/University/year2.txt
Where the first argument is the output directory and ~/bkp/University/University/year2.txt is a list of absolute paths to search for source audio files. These could be obtained with a find command:
find ./year2 -name "*.MP3" -type f -exec realpath '{}' \; > year2.txt
Speeding up bulk transcriptions
I was happy with the quality of my transcriptions now. Obtaining them could now be achieved with a single simple command. Overall, the core functionality I wanted to build was now there and it was sufficient to accurately transcribe an entire computer science lecture. The problem was, I had another 150 lectures to transcribe after that first one and each one took a bit more than a minute to fully process.
Compared to other speech-to-text services I’d used before (Google), which would take several minutes to return a result, a minute to obtain a full transcript for a noisy 50-minute audio was a great improvement. You might even argue transcribing 3 years’ worth of lectures in a little over 2 hours is not that bad, all things considered.
Can we not make it go quicker though? This script relies heavily on blocking network calls to communicate with the Whisper API. Perhaps Python co-routines could help us more efficiently process multiple different audio chunks.
def export_to_chunks(self, chunk_duration_mins, output_path="."):
print(f"Output path: {output_path}")
audio_chunks = self.file[::chunk_duration_mins]
print("Splitting audio into chunks")
chunk_filename_idx = 1
chunk_paths = []
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
for chunk in audio_chunks:
chunk_path = f"{output_path}/{self.fileinfo.file_basename}-chunk-{chunk_filename_idx}{self.fileinfo.file_ext}"
chunk_paths.append(chunk_path)
executor.submit(self.export_chunk, chunk, chunk_path)
chunk_filename_idx = chunk_filename_idx + 1
executor.shutdown()
return chunk_paths
This yielded the following results:
Output path: /tmp/tmplh90ucl8
Splitting audio into chunks
Exporting chunk to /tmp/tmplh90ucl8/Lecture-123-chunk-1.mp3...
Exporting chunk to /tmp/tmplh90ucl8/Lecture-123-chunk-2.mp3...
Exporting chunk to /tmp/tmplh90ucl8/Lecture-123-chunk-3.mp3...
Time elapsed exporting chunks: 60.45975144199474
That is slightly better, but we can do better. Another expensive operation the script carries out is the disk operations to read the audio files and to write their chunks back out to the local filesystem. We could perform each action in a separate thread so they can be executed in parallel.
Below, you’ll find a code snippet that demonstrates my implementation of the multi-threaded pydub chunking process. This was my first time writing asynchronous and multi-threaded applications in Python, and I was delighted to find that the standard APIs were both user-friendly and familiar. Key features included the use of context managers for threading implementation and the introduction of the async/await keywords, which bear similarities in semantics to those found in other languages, such as JavaScript.
def export_to_chunks(self, chunk_duration_mins, output_path="."):
print(f"Output path: {output_path}")
audio_chunks = self.file[::chunk_duration_mins]
print("Splitting audio into chunks")
chunk_filename_idx = 1
chunk_paths = []
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
for chunk in audio_chunks:
chunk_path = f"{output_path}/{self.fileinfo.file_basename}-chunk-{chunk_filename_idx}{self.fileinfo.file_ext}"
chunk_paths.append(chunk_path)
executor.submit(self.export_chunk, chunk, chunk_path)
chunk_filename_idx = chunk_filename_idx + 1
executor.shutdown()
return chunk_paths
Combining Python co-routines and threads to process the audio files more efficiently allowed me to more than half the average file transcription time, down to 25 seconds!
Output path: /tmp/tmpp9qbdrvh
Splitting audio into chunks
Exporting chunk to /tmp/tmpp9qbdrvh/Lecture-123-chunk-1.mp3...
Exporting chunk to /tmp/tmpp9qbdrvh/Lecture-123-chunk-2.mp3...
Exporting chunk to /tmp/tmpp9qbdrvh/Lecture-123-chunk-3.mp3...
Done
Done
Done
Time elapsed exporting chunks: 25.875500107002154
Next Steps
Some additional improvements which I could implement in the future include:
- Provide an initial seed prompt with adequate spelling to disambiguate some terms commonly found in an academic or technical setting. This should also help with Whisper API sometimes not capitalising the “I” pronoun correctly, e.g. “i’m going to show you…” instead of “I’m going to show you…”, or formatting certain technical terms like “.NET” correctly.
- Improve transcription accuracy by passing the tail end of a processed chunk as a context prompt to the subsequent chunk transcription API call.
- Incorporate the
paragraphs.pyscript as a library extension to the main Python application so that it doesn’t need to be invoked separately.
Conclusion
Overall, I am very satisfied with the results I’ve obtained from OpenAI’s WhisperAPI. I find the API is easy to use, efficient and uncannily accurate, even when given input audio that is far from being optimal. Is Whisper API flawless then? No, definitely not.
Even though the accuracy of its transcriptions is consistently high, it does produce a low proportion of non-sensical sentences and it doesn’t always get every term right. I believe these minor accuracy problems can be easily overcome with better source audio quality as well as careful use of prompting in the API calls to provide the necessary context to disambiguate certain complicated terms. Considering the trajectory of its sister model GPT-4, I am convinced future iterations of the Whisper model will be either even faster or more accurate, or even both at the same time.
Now, if you’ll excuse me, I must leave to review my lecture notes on the differences between CORBA and RMI distributed communication protocols. I’ve got an important exam coming up soon…