The Password Input Bomb Experiment
I was faced with an interesting question related to web security recently: are data-fuelled denial of service attacks possible against modern Next.js web applications?
Picture a server-side rendered Next.js application which exposes a login endpoint expecting a JSON payload like this:
{
"username": "xx.darkangel.xx@gmail.com",
"password": "hunter22"
}
Would it be possible to supply a string of data in either (or both) fields so large that the Node process powering the web server runs out of memory and crashes? Do modern frameworks like React and Next.js provide any safeguards against a basic security threat like this? Sure, interpreted languages like JavaScript are far less vulnerable to buffer overflow attacks than applications written carelessly in low-level languages like C but, are they completely safe from data exploits? I decided to find out with an experiment.
Mounting an attack from the client
Firstly, I want to learn if a React frontend can mitigate the issue of massive data input with a simple test. Let’s whip up a dumb page that renders a standard login form accepting a username and password, as well as an indicator pointing out the length and size in megabytes of the data we enter in the password field. The application is rendered in Next.js but there’s no SSR component to it.
Some parts of the page source are omitted for brevity, but it’s pretty much what you get after running create-next-app. You can find the full source of my POC repository here.
const getUtf8StringMiB = (string) => (new TextEncoder().encode(string)).length / 1024 / 1024;
export default function Home() {
const [username, setUsername] = useState('');
const [password, setPassword] = useState('');
const handleFormSubmit = async (e) => {
e.preventDefault();
const res = await fetch('/api/login', {
method: 'POST',
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json'
},
body: JSON.stringify({ username, password }),
});
console.log(await res.json());
};
return (
<div className={styles.container}>
<Head>
<title>Memory Overflow POC</title>
<meta name="description" content="Generated by create next app" />
<link rel="icon" href="/favicon.ico" />
</Head>
<main className={styles.main}>
<h1>Login</h1>
<form onSubmit={handleFormSubmit}>
<div className={styles['login-container']}>
<div>
<label htmlFor="username">Username:</label>
<input className={styles.field} name="username" onChange={(e) => setUsername(e.target.value)} />
</div>
<div>
<label htmlFor="password">Password:</label>
<input className={styles.field} name="password" onChange={(e) => setPassword(e.target.value)} />
</div>
<p>Password length: {password.length} characters ({getUtf8StringMiB(password)} MiB)</p>
<div>
<button type="submit" className={styles.button}>Submit</button>
</div>
</div>
</form>
</main>
</div>
);
}
This bit of JSX will display something like this:
The best way to hide something is in plain sight
And on submit, it will post a JSON payload like this to the /api/login endpoint fulfilled by the Next API server listening on the other end:
// POST /api/login
{
"username": "email@example.com",
"password": "hunter22"
}
The server will respond with this:
REQ: Sat Jun 11 2022 12:14:24 GMT+0100 (British Summer Time)
{
message: 'ok',
username: 'email@example.com',
receivedPasswordLength: 8
}
Here is the server code:
import { resourceUsage } from 'node:process';
import * as v8 from 'node:v8';
// Print memory utilisation stats when the server launches
console.log(resourceUsage());
console.log("Memory usage", process.memoryUsage());
console.log(v8.getHeapStatistics());
export default function handler(req, res) {
const { username, password } = req.body;
console.log(`REQ: ${new Date()}`);
const responseBody = { message: 'ok', username, receivedPasswordLength: password.length };
console.log(responseBody);
res.status(200).json(responseBody);
}
We will focus our efforts on abusing the password field specifically, but any field that accepts arbitrary user input with no length restriction would work too. The server will respond with the length of the password string it was sent so we can be sure the password is arriving correctly and no truncation occurs along the way.
Will React impose any input rules to protect these fields from becoming too large? Using the String.repeat() function, I’ve set the password field to input strings of increasing size using the in-built Chrome JS console:
// I selected the element in my browser DevTools to be able to reference
// it using the `$0` console pseudo-variable below
> $0.value = 'a'.repeat(n)
where n is the desired input length: 20 characters, 128, 2,000, 200,000… Past a certain point I switched to powers of 2 to attain much bigger lengths.
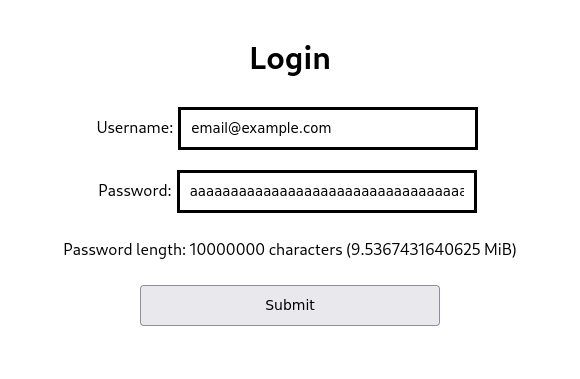
In Chrome, I was able to insert string lengths up to 2^26 (64 MiB) into the field using this method.
However, all of my form submissions past a certain point were met with the following response from the Next API server:
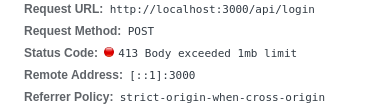
Well, there you go! Right off the bat, the server successfully deflected my request with a “HTTP 413: Body exceeded 1mb limit” response, and of course, it kept on running. It turns out this is the default maximum request body size in Next and Express web servers.
Okay! A Next 12 application comes with some sensible request validation rules out of the box, such as a 1 MB limit on the size of incoming HTTP requests.
For good measure, I crafted a very similar, barebones vanilla Express API server and sent the same request to it. Express applications are more lightweight and far more popular, so there may be a big attack surface to exploit there. Express handled the exceedingly large request in a similar fashion, outputting this error instead:
PayloadTooLargeError: request entity too large
at readStream (/home/dvejmz/workspace/express/node_modules/raw-body/index.js:156:17)
at getRawBody (/home/dvejmz/workspace/express/node_modules/raw-body/index.js:109:12)
at read (/home/dvejmz/workspace/express/node_modules/body-parser/lib/read.js:79:3)
at jsonParser (/home/dvejmz/workspace/express/node_modules/body-parser/lib/types/json.js:135:5)
at Layer.handle [as handle_request] (/home/dvejmz/workspace/express/node_modules/express/lib/router/layer.js:95:5)
at trim_prefix (/home/dvejmz/workspace/express/node_modules/express/lib/router/index.js:328:13)
at /home/dvejmz/workspace/express/node_modules/express/lib/router/index.js:286:9
at Function.process_params (/home/dvejmz/workspace/express/node_modules/express/lib/router/index.js:346:12)
at next (/home/dvejmz/workspace/express/node_modules/express/lib/router/index.js:280:10)
at expressInit (/home/dvejmz/workspace/express/node_modules/express/lib/middleware/init.js:40:5)
Phew! The Express app didn’t crash either and was able to fulfil subsequent requests without a problem. The raw-body HTTP parsing library provides the input size sanity checking capabilities found in Express and Next.js. Removing this layer as well in this experiment would be pointless as that wouldn’t be representative of the typical Node.js web application you would find on the internet.
At this point you could argue the experiment has proved that any default installation of a Next.js or Express web server would be protected from a naive attack such as this. But what if said limit wasn’t there? For the sake of science and discovery, let’s push through this request size restriction and find out what would happen if modern web frameworks didn’t provide basic request validation like this. There could be a subset of web apps that would increase this limit to handle big file uploads anyway, so they may still be exposed to this exploit.
Finding the breaking point
To raise the maximum request body size limit in Next.js you have to add this config snippet to the Next API endpoint source to override its default setting of 1 MB.
export const config = {
api: {
bodyParser: {
sizeLimit: '2gb' // Setting the limit to 2 GB to accept ample payloads
}
}
};
REQ: Sun Jul 24 2022 15:32:21 GMT+0100 (British Summer Time)
{ message: 'ok', username: '', receivedPasswordLength: 67108865 }
Ok, we’re back on track now. Let’s continue to find out how far we can go until something breaks. Once I exceeded the 2^26 bytes mark, my Chrome browser tab crashed with an Illegal Instruction (SIGILL) error.
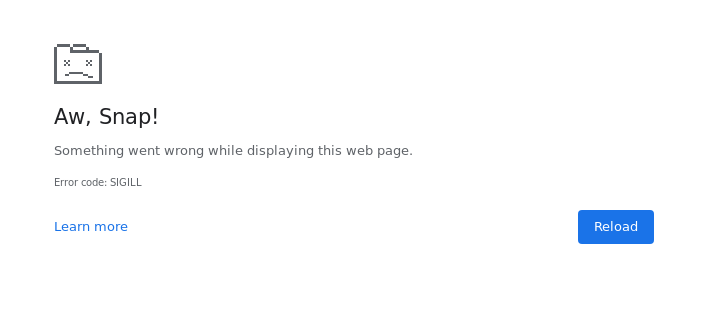
It is peculiar that providing a string longer than 2^29 causes a totally different type of error though:

The latter error is down to a deliberate cap on the maximum string length the V8 engine is able to store in memory. The limit is exactly 2^29 bytes on 64-bit machines.
This makes sense as I can generate strings up to this length in the Node REPL. So where do the SIGILL errors come from? React? Chrome? I decided to run this test on Firefox to find out if a completely different JavaScript engine would handle this another way.
On Firefox, React broke before the browser, as Firefox is happy to take string lengths one order of magnitude higher than Chrome.
filename: "webpack-internal:///./node_modules/react-dom/cjs/react-dom.development.js"
lineNumber: 1658
message: ""
name: "NS_ERROR_OUT_OF_MEMORY"
result: 2147942414
stack: "set@webpack-internal:///./node_modules/react-dom/cjs/react-dom.development.js:1658:11\n@debugger eval code:1:16\n"
I don’t know what leads to Chrome yielding a SIGILL error when given string lengths of this size but I decided not to pursue this thought anymore as it wasn’t that pertinent to the objective of my experiment.
Attacking the API
By design, most browsers impose hard caps on how long strings can get, which makes it more difficult to use them as a vehicle to deliver attacks that harness data overflow vulnerabilities. However, that is hardly a blocker for any motivated attacker. The React browser frontend can be easily bypassed, as payloads of any size can be posted directly to its backing API layer.
At first I tried writing a quick Node script to generate a JSON payload of arbitrary byte length and post it off to the login API endpoint (as a matter of fact I did, the script is available on the repo too). Alas, I soon hit the same roadblock I had prior encountered: the 512 MB restriction imposed by the V8 engine. This means that a Node process forked from a Node binary compiled from the upstream V8 sources will be unable to hold a string variable greater than 512 MB in size. Of course, there are elegant workarounds for this restriction, such as Streams but that is beyond the scope of this naive brute-force experiment. So what can we do then?
cURL to the rescue
One could generate a JSON file as big as allowed by their filesystem and send it across in a HTTP POST request via cURL. Something like this ought to do the trick:
curl -X POST \
-H 'Content-Type: application/json' \
--data-binary "@./massive-file.json" \
http://localhost:3000/api/login
Plain and simple! How do we generate a massive JSON file though? Can’t use Node for that, so a simple C application will do.
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
FILE *fil = fopen("./overflow.json", "w");
if (fil == NULL) {
return 1;
}
const int length_GB = 1;
const size_t len = (length_GB * 1000 * 1000 * 1000) + 3;
char *password = malloc(len);
if (password == NULL) {
return 1;
}
fprintf(fil, "%s", "{\"password\":\"");
for (int i = 0; i < len; ++i) {
password[i] = '1';
}
password[len - 3] = '\"';
password[len - 2] = '}';
password[len - 1] = '\0';
fprintf(fil, "%s", password);
fclose(fil);
return 0;
}
Tweaking the value of the length_GB integer yields JSON files of any length in gigabytes, containing a payload our Next API can accept. No more obstacles in the way!
$ gcc -o overflow ./overflow.c
$ ./overflow
$ curl -X POST -H 'Content-Type: application/json' --data-binary "@./overflow.json" http://localhost:3000/api/login
curl: (56) Recv failure: Connection reset by peer
Server response:
RangeError: Invalid string length
at IncomingMessage.onData (/home/dvejmz/dev/misc/node-mem-overflow/next/node_modules/next/dist/compiled/raw-body/index.js:28:2016)
at IncomingMessage.emit (events.js:400:28)
at addChunk (internal/streams/readable.js:293:12)
at readableAddChunk (internal/streams/readable.js:267:9)
at IncomingMessage.Readable.push (internal/streams/readable.js:206:10)
at HTTPParser.parserOnBody (_http_common.js:140:24)
error Command failed with exit code 1.
There you finally have it, a crash!
Conclusion
My little experiment has successfully shown that a typical Next.js/Express web server installation should be able to handle basic Denial of Service attacks that rely on crafting exceedingly large request payloads to overrun the server’s capacity to hold that much data for a single variable in memory.
This may be a risk to consider in other server-side web platforms like PHP, .NET or Java Spring but two of the most popular JavaScript frameworks at present have proved to be hardened enough to render this type of aggression harmless with their sensible default settings. Developers must be wary of lifting these sensible settings, as that could lead to unforeseen consequences.